
In the previous post, we ran through an extended example of a mixed-effects modelling analysis of the ML lexical decision data. We ended the post by getting p-values for the effects of the predictors included in our model. That was the model apparently justified by a likelihood ratio test comparison of maximum likelihood (REML=F) models varying in fixed effects but constant in possessing random effects of subjects and items on intercepts.
You will recall that I said in that post that:
In following posts, we shall 1. perform some checks on whether the fixed effects appear justified with respect to data hygiene 2. examine what random effects seem justified, looking at random effects on intercepts and random effects on slopes.
— that will happen but I want to consider some of the words I am using.

Creative commons – flickr – Florida Memory: Fisherman with his son, Naples, Florida, 1949
I am reading the great introductory text on multilevel modeling by Snijders & Boskers (2004). There, they begin their book with a clear, simple, explanation of the normal data collection situation for many of us.
You will know that statistical models, for example, ordinary least squares (OLS) regression assume that observations should be sampled independently. In regression, the distribution of errors – the differences between model prediction and data observation for any observation – should consist of errors with a normal distribution, with any one error independent of any other. If we think about the normal situation in which we find ourselves, that independence assumption will be invalid. Most of the time, we are asking participants to read some set of words, and everyone will be asked to read all the words. If you plot the participants’ data or the responses to each item, you will see that, as you might expect, some people are slow and some fast for most responses to most words, while some words are easy and some hard for most people.
You can consider this illustration of some reading data, as an illustration of that point.
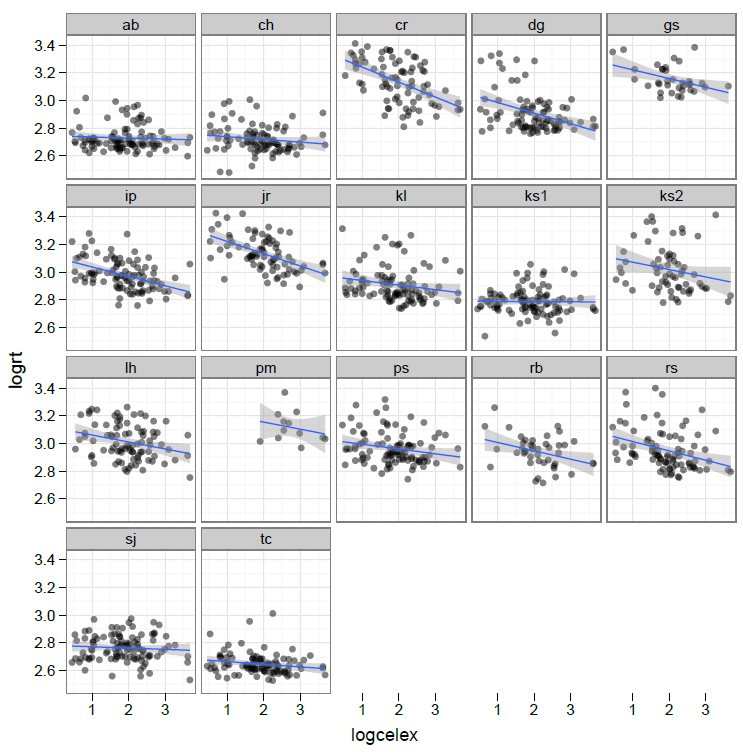
Notice:
— Each participant in this study of reading aloud was an adult and each was asked to read the same set of about 100 words out loud.
— The lattice of plots shows:
1. The average RT for each person – and for each word – varied. You might guess what the average over all people or all words would be. Now consider how each person’s average RT varies from the average RT over all people, or how each word’s average RT varies from the average RT over all words. The average outcome is called the intercept, a term you will have encountered before in regression. Estimating the deviation of a person or a word from the overall average is a matter of estimating random effects on person or word on intercepts, or, random intercepts. In the mixed effects modeling code in R, we designate this as:

2. The slope of the effect of, here, frequency on reading RT also appears to vary between people. There might be an average effect of frequency on RT overall. You could call the frequency effect the fixed effect here. We can see that, most of the time, more frequent words are associated with shorter RTs. However, the slope of that effect is more or less steep for some people. That variation in slope can be estimated as random effects of person on slopes, or random slopes. However, the variation in the frequency effect might also be considered to be of theoretical interest and, critically, it might be captured by, for example, an interaction between the effect of frequency and the effect of some participant attribute that conditions or modulates the frequency effect by a systematic (rather than a random) person effect.
Let’s return to Snijders & Boskers (2004). They note that one can often, for reasons of efficiency (consider how much easier it is to give everybody the same sample of words than different samples) or other pragmatic considerations, that data collection often proceeds through multistage sampling. One might test in a set of schools, a sample of schools, and in those schools test samples of children. It is a mistake to consider that the children are sampled independently (an assumption you would be making if you applied OLS regression to such data). That is because the children are clearly grouped by school (and thus not independent samples). Similarly, it would be clearly a mistake to consider that the observations for each person or each word are somehow independent. They are dependent because the data can be considered to cluster or group by person or by word. The consequence of ignoring this structure will be inflated Type I error rate, or finding things that are not really there.
Snijders & Boskers (2009) next point out, however, that if data are collected in multistage sampling we might, for theoretical or practical reasons, want to make inferences about effects occurring at each stage. (This is also noted by Baayen, Davidson & Bates (2008) in comments that led me to consider how the effects of item attributes might vary between readers systematically rather than merely at random.) We might want to know how school environment or policy affects teacher practice or how both school policy and teacher attitudes affect student performance. We might want to know how the kind of reader you are affects reading performance but also how the kind of word you read affects performance. We might, further, be interested in how effects that operate at one level or over one kind of cluster interact with effects operating at other levels or over other kinds of cluster.
The more that observations within a cluster are similar to each other (compared to other clusters) the more we might be concerned about the characteristics of the cluster, the higher level units.
We must not forget longitudinal observations, and shall return to the situation where data are clustered because people are tested repeatedly over time.
Reading
Snijders, T.A.B., & Bosker, R.J. (2004). Multilevel analysis: An introduction to basic and advanced multilevel modeling. London: Sage Publications Ltd.
