
As noted in a previous post, our mixed effects analysis of the ML lexical decision data suggested that RTs were influenced by significant effects due to:
cAge + cART + cTOWRENW +
cLength + cOLD + cBG_Mean + cLgSUBTLCD + cIMG +
cTOWRENW:cLgSUBTLCD + cAge:cLength + cAge:cOLD + cAge:cBG_Mean
I am writing the interactions not as var1*var2 but as var1:var2 – the second form of expressing an interaction restricts the analysis to considering just that product term.
I have been advised to check whether such effects are dependent in some way on the presence of other, nonsignificant effects (I think this recommendation might be in Baayen, 2008, but I know it has come to me also through other channels). That check can take the form of a re-analysis of the data with a model (REML = FALSE) including just the significant effects from the first analysis.
For our situation, the code for doing that model would be written as follows:
# we can check if the significant effects are influenced by the presence of nonsig effects by rerunning the model # first removing all but the significant effects full.lmer5 <- lmer(log(RT) ~ cAge + cART + cTOWRENW + cLength + cOLD + cBG_Mean + cLgSUBTLCD + cIMG + cTOWRENW:cLgSUBTLCD + cAge:cLength + cAge:cOLD + cAge:cBG_Mean + (1|subjectID) + (1|item_name), data = nomissing.full, REML = FALSE) print(full.lmer5,corr=F) pvals.fnc(full.lmer5)$fixed
And, in fact, you can see that some effects that were significant do not remain so once you take out all the effects that were not significant in the previous, full, model.
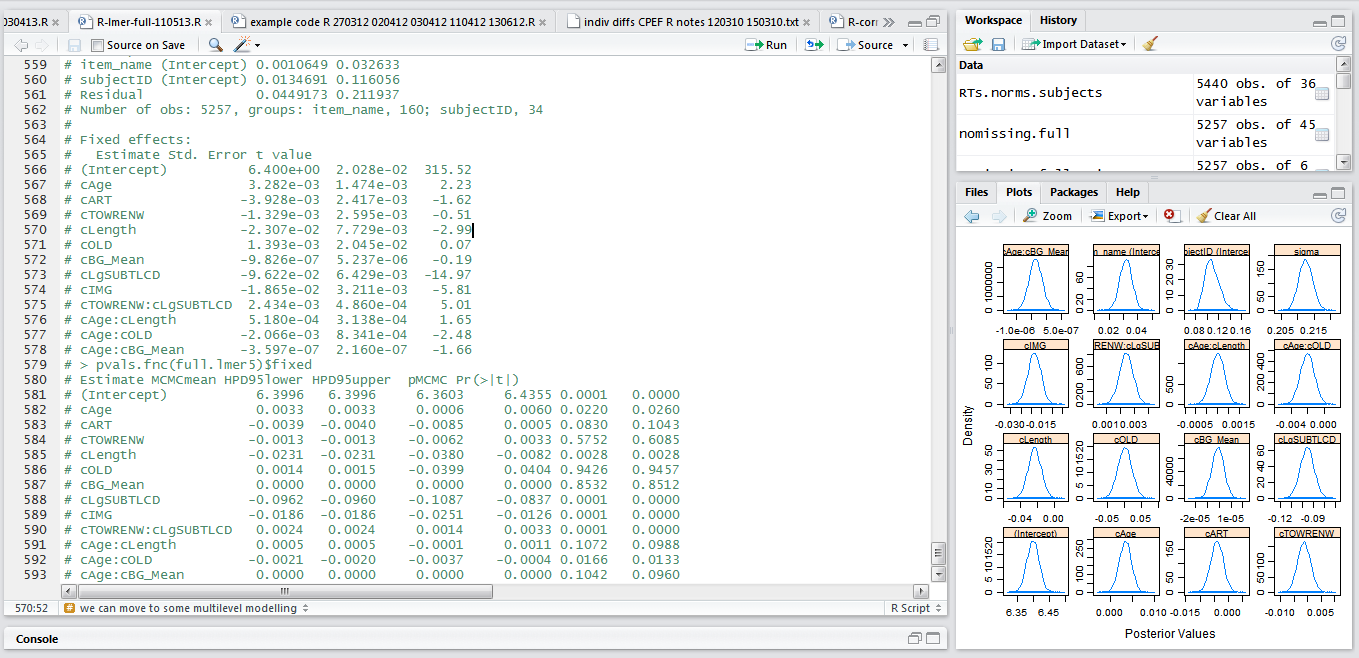
Notice:
— The effects of age, length, frequency, imageability, the interaction between the nonword reading skill and the frequency effects, and between the age and orthographic OLD effect, remain significant while the others are rendered either nonsignificant or marginal.
— We included main effects even if not originally significant, if they had been part of a significant interaction: the interaction is what counts but the main effect (to use the ANOVA term) has to be in the model for it to be properly specified.
I would also note that some authors do not recommend the removal of nonsignificant effects (e.g. Harrell, 2001) and I think that that would be my inclination also. I have found that the significance of some effects – the flakier, or more delicate, and also often the effects of most interest – may move around depending on what else is also specified for the model. That is what you might call a pragmatic emotional concern – the instability is worrisome – but this is an instability that also reflects the impact on effect of estimation of modifications in the predictor space. We could argue that the model should be the most complex that can be found to be justified.
What have we learnt
(The code used to run this analysis can be found here.)
That some effects might be dependent on the presence of other non-significant effects.
Note the key vocabulary in the use of X:Y rather than X*Y interaction notation; see Baayen (2008) for further explanation.
Reading
Baayen, R. H. (2008). Analyzing linguistic data: Cambridge University Press.
Harrell Jr, F. J. (2001). Regression modelling strategies: With applications to linear models, logistic regression, survival analysis. New york, NY: Springer.
Snijders, T.A.B., & Bosker, R.J. (2004). Multilevel analysis: An introduction to basic and advanced multilevel modeling. London: Sage Publications Ltd.
